Language Models Represent Beliefs of Self and Others



TL;DR: LLMs internally represent beliefs of themselves and other agents, and manipulating these representations can significantly impact their Theory of Mind reasoning capabilities.
Abstract
Understanding and attributing mental states, known as Theory of Mind (ToM), emerges as a fundamental capability for human social reasoning. While Large Language Models (LLMs) appear to possess certain ToM abilities, the mechanisms underlying these capabilities remain elusive. In this study, we discover that it is possible to linearly decode the belief status from the perspectives of various agents through neural activations of language models, indicating the existence of internal representations of self and others' beliefs. By manipulating these representations, we observe dramatic changes in the models' ToM performance, underscoring their pivotal role in the social reasoning process. Additionally, our findings extend to diverse social reasoning tasks that involve different causal inference patterns, suggesting the potential generalizability of these representations.
Discovering the Belief Representations

We prompt the model with pairs of story and belief, and use the attention head activations to decode the belief status of different agents. We focus on two agents, namely protagonist, the central figure of the narrative, and oracle, which represents an omniscient spectator's perspective.
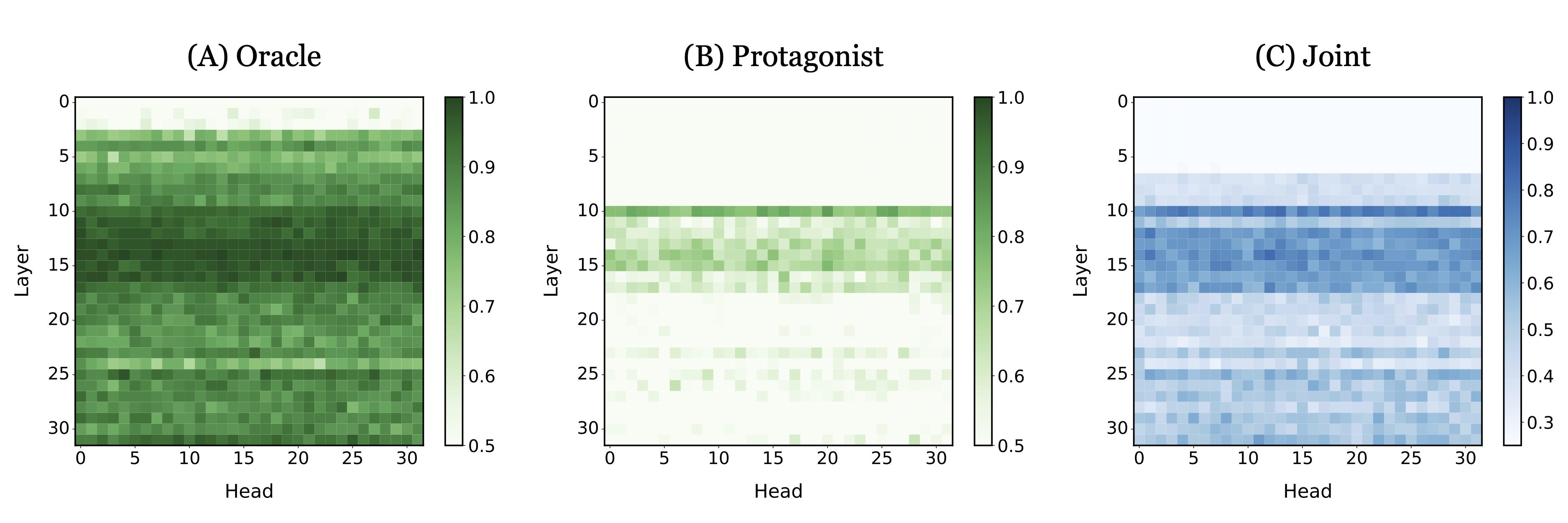
We find that even with models as simple as linear regression, it is possible to decode the belief status of both agents, either separately or jointly, from a specific group of attention heads. Notably, there exist more activation heads that could represent the oracle belief than those representing the protagonist's belief.
Belief Manipulation
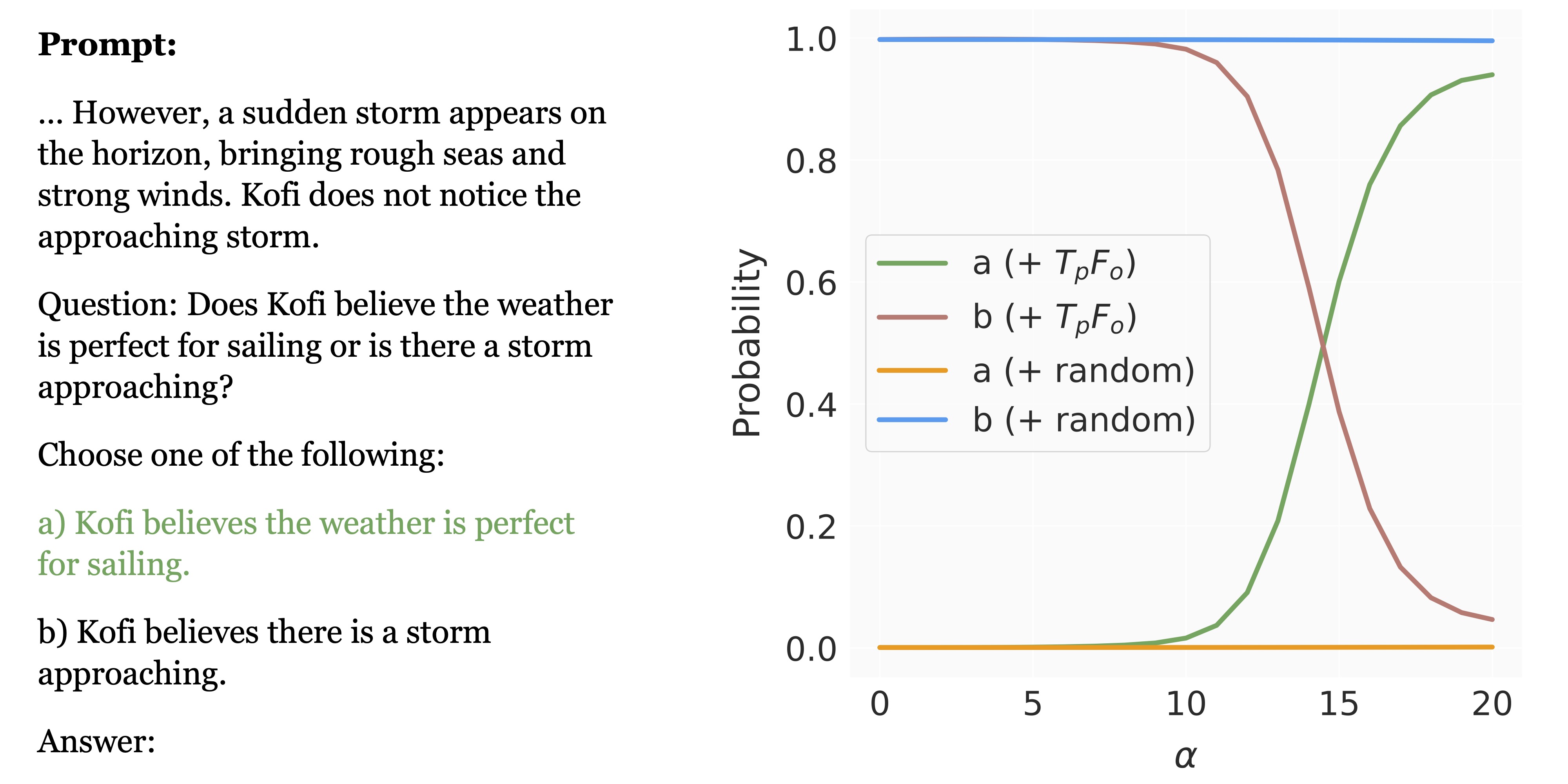
We discover that steering head activations towards the belief directions identified through multinomial probing significantly affects the model's ToM capability, whereas manipulation in random directions results in negligible change.
Deciphering the Belief Representations
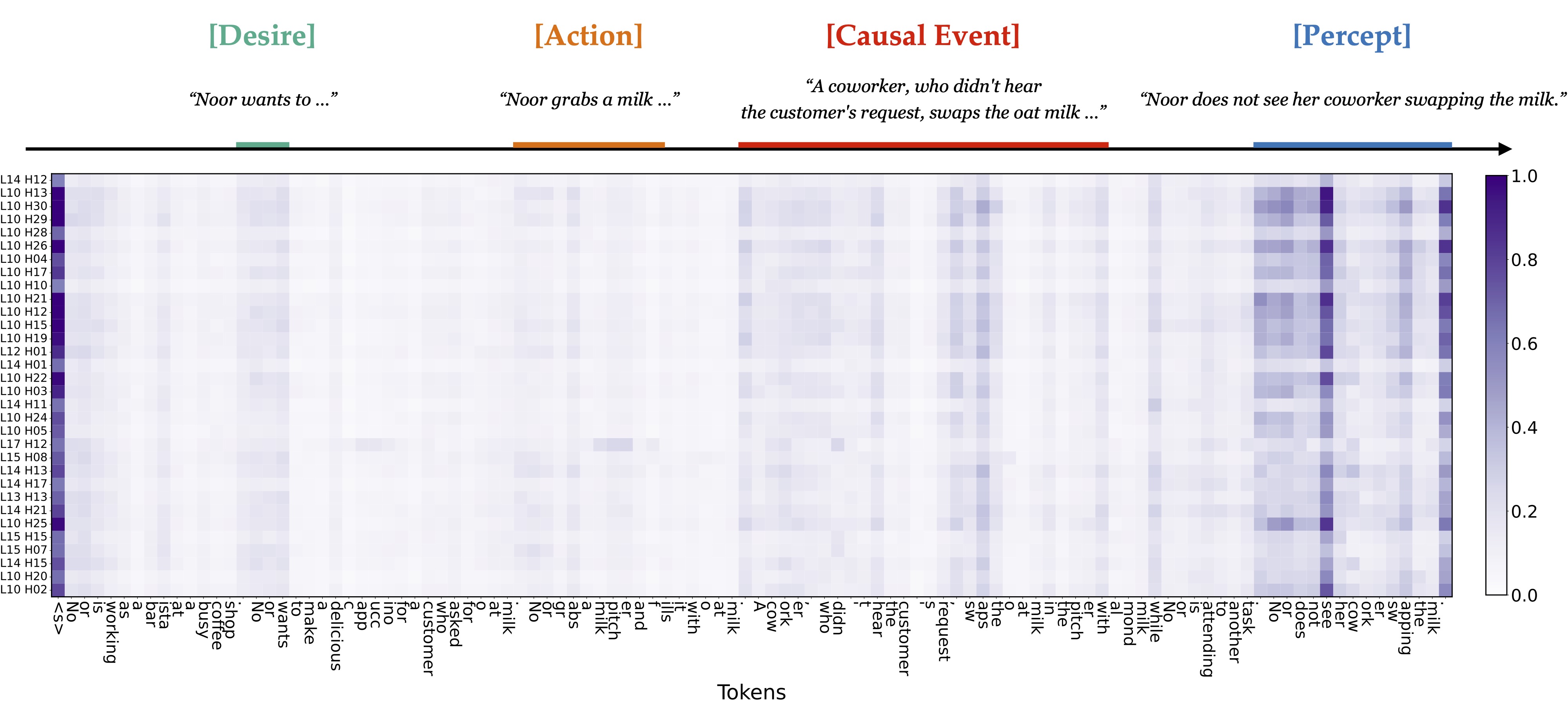
Furthermore, we seek to understand which input tokens are most relevant to the identified belief directions. We project the neural activations onto the belief directions and back-propagate to the input token embedding space. Remarkably, this process precisely localizes the key causal variables within the prompt, including the protagonist's desires and initial actions, the causal event that changes the environmental states, and the protagonist’s percept status of the causal event. These elements collectively enable a comprehensive inference of both agents' beliefs. These observations may also account for the generalizability of the belief directions across different social reasoning tasks.